
背景信息
內容簡介
在大模型時代,隨著模型效果的顯著提升,模型評測的重要性日益凸顯。科學、高效的模型評測,不僅能幫助開發者有效地衡量和對比不同模型的性能,更能指導他們進行精準地模型選擇和優化,加速AI創新和應用落地。因此,建立一套平臺化的大模型評測最佳實踐愈發重要。
本文為PAI大模型評測最佳實踐,旨在指引AI開發人員使用PAI平臺進行大模型評測。借助本最佳實踐,您可以輕松構建出既能反映模型真實性能,又能滿足行業特定需求的評測過程,助力您在人工智能賽道上取得更好的成績。最佳實踐包括如下內容:
• 如何準備和選擇評測數據集
• 如何選擇適合業務的開源或微調后模型
• 如何創建評測任務并選擇合適的評價指標
• 如何在單任務或多任務場景下解讀評測結果
平臺亮點
PAI大模型評測平臺,適合您針對不同的大模型評測場景,進行模型效果對比。例如:
• 不同基礎模型對比:Qwen2-7B-Instruct vs. Baichuan2-7B-Chat
• 同一模型不同微調版本對比:Qwen2-7B-Instruct 在私有領域數據下訓練不同 epoch 版本效果對比
• 同一模型不同量化版本對比:Qwen2-7B-Instruct-GPTQ-Int4 vs. Qwen2-7B-Instruct-GPTQ-Int8
考慮到不同開發群體的特定需求,我們將以企業開發者與算法研究人員兩個典型群體為例,探討如何結合常用的公開數據集(如MMLU、C-eval等)與企業的自定義數據集,實現更全面準確并具有針對性的模型評測,查找適合您業務需求的大模型。最佳實踐的亮點如下:
• 端到端完整評測鏈路,無需代碼開發,支持主流開源大模型,與大模型微調后的一鍵評測;
• 支持用戶自定義數據集上傳,內置10+通用NLP評測指標,一覽式結果展示,無需再開發評測腳本;
• 支持多個領域的常用公開數據集評測,完整還原官方評測方法,雷達圖全景展示,省去逐個下載評測集和熟悉評測流程的繁雜;
• 支持多模型多任務同時評測,評測結果圖表式對比展示,輔以單條評測結果詳情,方便全方位比較分析;
• 評測過程公開透明,結果可復現。評測代碼開源在與ModelScope共建的開源代碼庫eval-scope中,方便細節查看與復現:
https://github.com/modelscope/eval-scope
前提條件
• 已開通PAI并創建了默認工作空間。具體操作,請參見開通PAI并創建默認工作空間。
• 如果選擇自定義數據集評測,需要創建OSS Bucket存儲空間,用來存放數據集文件。具體操作,請參見控制臺創建存儲空間。
使用費用
• PAI大模型評測依托于PAI-快速開始產品。快速開始是PAI產品組件,集成了眾多AI開源社區中優質的預訓練模型,并且基于開源模型支持零代碼實現從訓練到部署再到推理的全部過程,給您帶來更快、更高效、更便捷的AI應用體驗。
• 快速開始本身不收費,但使用快速開始進行模型評測時,可能產生DLC評測任務費用,計費詳情請參見DLC計費說明。
• 如果選擇自定義數據集評測,使用OSS存儲,會產生相關費用,計費詳情請參見OSS計費概述。
場景一:面向企業開發者的自定義數據集評測
企業通常會積累豐富的私有領域數據。如何充分利用好這部分數據,是企業使用大模型進行算法優化的關鍵。因此,企業開發者在評測開源或微調后的大模型時,往往會基于私有領域下積累的自定義數據集,以便于更好地了解大模型在私有領域的效果。
對于自定義數據集評測,我們使用NLP領域標準的文本匹配方式,計算模型輸出結果和真實結果的匹配度,值越大,模型越好。使用該評測方式,基于自己場景的獨特數據,可以評測所選模型是否適合自己的場景。
以下將重點展示使用過程中的一些關鍵點,更詳細的操作細節,請參見模型評測產品文檔。
1. 準備自定義評測集
1.1. 自定義評測集格式
1. 基于自定義數據集進行評測,需要提供JSONL格式的評測集文件
o 文件格式:使用question標識問題列,answer標識答案列。
o 文件示例:llmuses_general_qa_test.jsonl

2. 符合格式要求的評測集,可自行上傳至OSS,并創建自定義數據集,詳情參見上傳OSS文件和創建及管理數據集。
1.2. 創建自定義評測集
1. 登錄PAI控制臺。
2. 在左側導航欄選擇AI資產管理>數據集,進入數據集頁面
3. 單擊創建數據集
4. 填寫創建數據集相關表單,從OSS中選擇您的自定義評測集文件
2. 選擇適合業務的模型
2.1. 查找開源模型
1. 在PAI控制臺左側導航欄選擇快速開始,進入快速開始頁面
2. 單擊快速開始提供的模型分類信息,直接進入到模型列表中,根據模型描述信息進行查看。

3. 單擊進入模型詳情頁后,對于可評測的模型,會展示評測按鈕。
a. 支持模型類型:當前模型評測支持HuggingFace所有AutoModelForCausalLM類型的模型
2.2. 使用微調后的模型
1. 使用快速開始進行模型微調,詳細步驟請參見模型部署及訓練
2. 微調完成后,在快速開始>任務管理>訓練任務中,單擊訓練好的任務名稱,進入任務詳情頁后,對于可評測的模型,右上角會展示評測按鈕。
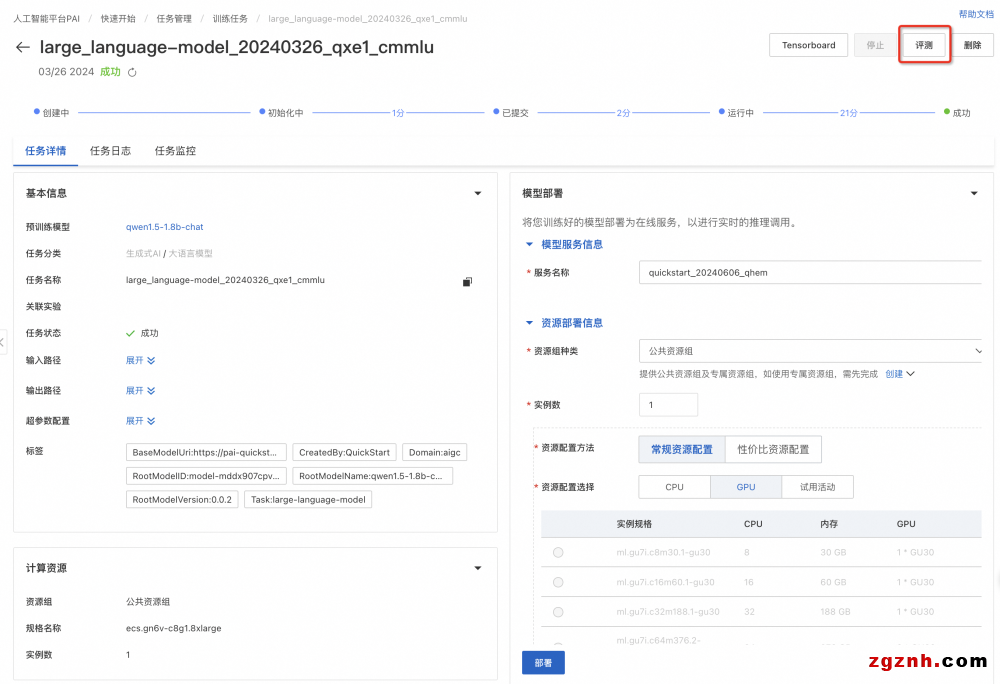
3. 創建評測任務
1. 在模型詳情頁右上角單擊評測,創建評測任務
2. 在新建評測任務頁面,配置以下關鍵參數。

3. 任務創建成功后,將自動分配資源,并開始運行。
4. 運行完成后,任務狀態顯示為已成功。
4. 查看評測結果
4.1. 評測任務列表
1. 在快速開始頁面,單擊搜索框左側的任務管理。
2. 在任務管理頁面,選擇模型評測標簽頁。
4.2. 單任務結果
1. 在模型評測列表頁,單擊評測任務的查看報告選項,即可進入評測任務詳情頁
2. 評測報告如下圖所示,選擇自定義數據集評測結果,將在雷達圖展示該模型在ROUGE和BLEU系列指標上的得分。此外還會展示評測文件每條數據的評測詳情。

• rouge-n類指標計算N-gram(連續的N個詞)的重疊度,其中rouge-1和rouge-2是最常用的,分別對應unigram和bigram,rouge-l 指標基于最長公共子序列(LCS)。
• bleu (Bilingual evaluation Understudy) 是另一種流行的評估機器翻譯質量的指標,它通過測量機器翻譯輸出與一組參考翻譯之間的N-gram重疊度來評分。其中bleu-n指標計算n-gram的匹配度。
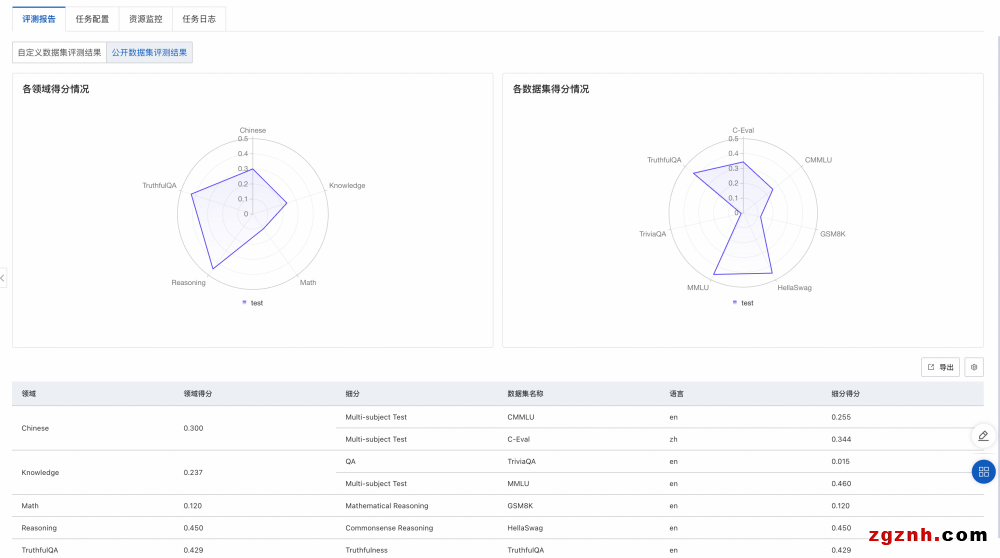
3. 最終評測結果會保存到您指定的OSS路徑中
4.3. 多任務對比
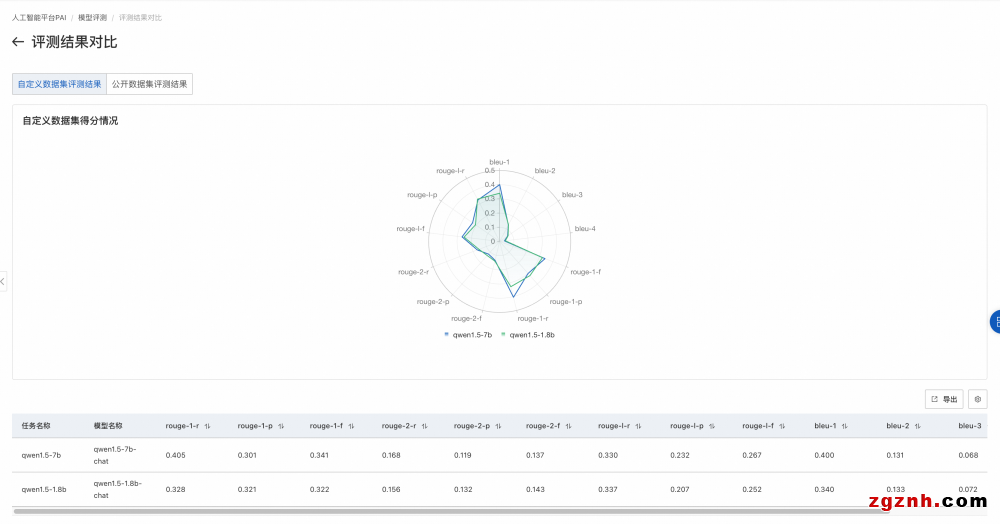
1. 當需要對比多個模型的評測結果時,可以將它們聚合在一個頁面上展示,以便于比較效果。
2. 具體操作為在模型評測任務列表頁,左側選擇想要對比的模型評測任務,右上角單擊對比,進入對比頁面。
3. 自定義數據集評測對比結果
場景二:面向算法研究人員的公開數據集評測
算法研究通常建立在公開數據集上。研究人員在選擇開源模型,或對模型進行微調后,都會參考其在權威公開數據集上的評測效果。然而,大模型時代的公開數據集種類繁多,研究人員需要花費大量時間調研選擇適合自己領域的公開數據集,并熟悉每個數據集的評測流程。為方便算法研究人員,PAI接入了多個領域的公開數據集,并完整還原了各個數據集官方指定的評測metrics,以便獲取最準確的評測效果反饋,助力更高效的大模型研究。
在公開數據集評測中,我們通過對開源的評測數據集按領域分類,對大模型進行綜合能力評估,例如數學能力、知識能力、推理能力等,值越大,模型越好,這種評測方式也是大模型領域最常見的評測方式。
以下將重點展示使用過程中的一些關鍵點,更詳細的操作細節,請參見模型評測產品文檔。
1. 支持的公開數據集
目前PAI維護的公開數據集包括MMLU、TriviaQA、HellaSwag、GSM8K、C-eval、CMMLU、TruthfulQA,其他公開數據集陸續接中。

2. 選擇適合的模型
2.1. 查找開源模型
1. 在PAI控制臺左側導航欄選擇快速開始,進入快速開始頁面
單擊快速開始提供的模型分類信息,直接進入到模型列表中,根據模型描述信息進行查看。
3. 單擊進入模型詳情頁后,對于可評測的模型,會展示評測按鈕。
a. 支持模型類型:當前模型評測支持HuggingFace所有AutoModelForCausalLM類型的模型
2.2. 使用微調后的模型
1. 使用快速開始進行模型微調,詳細步驟請參見模型部署及訓練
2. 微調完成后,在快速開始>任務管理>訓練任務中,單擊訓練好的任務名稱,進入任務詳情頁后,對于可評測的模型,右上角會展示評測按鈕。
3. 創建評測任務
1. 在模型詳情頁右上角單擊評測,創建評測任務
2. 在新建評測任務頁面,配置以下關鍵參數。本文以MMLU數據集為例。

3. 任務創建成功后,將自動分配資源,并開始運行。
4. 運行完成后,任務狀態顯示為已成功。
4. 查看評測結果
4.1. 評測任務列表
1. 在快速開始頁面,單擊搜索框左側的任務管理。
2. 在任務管理頁面,選擇模型評測標簽頁。
4.2. 單任務結果
1. 在模型評測列表頁,單擊評測任務的查看報告選項,即可進入評測任務詳情頁
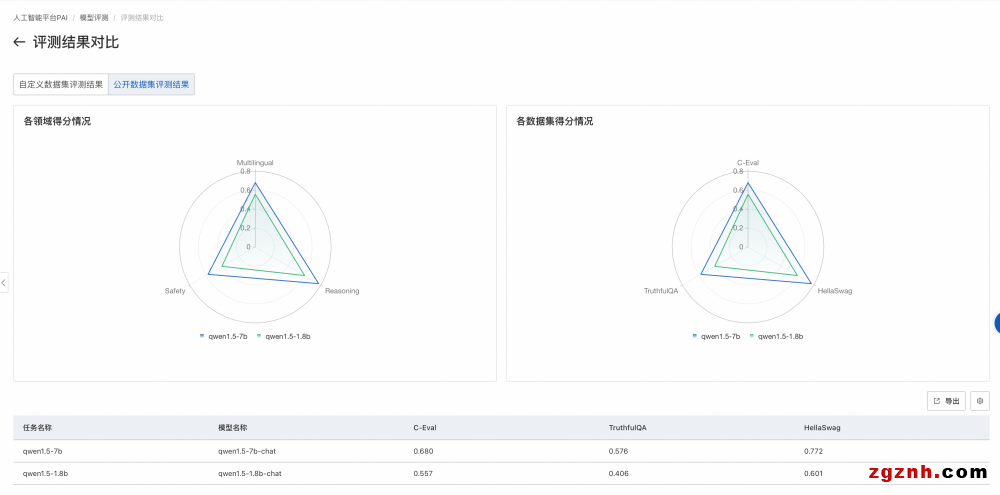
2. 評測報告如下圖所示,選擇公開數據集評測結果,將在雷達圖展示該模型在公開數據集上的得分。
o 左側圖片展示了模型在不同領域的得分情況。每個領域可能會有多個與之相關的數據集,對屬于同一領域的數據集,我們會把模型在這些數據集上的評測得分取均值,作為領域得分。
o 右側圖片展示模型在各個公開數據集的得分情況。每個公開數據集的評測范圍詳見該數據集官方介紹。
3. 最終評測結果會保存到您指定的OSS路徑中
4.3. 多任務對比
1. 當需要對比多個模型的評測結果時,可以將它們在聚合在一個頁面上展示,以便于比較效果。
2. 具體操作為在模型評測任務列表頁,左側選擇想要對比的模型評測任務,右上角單擊對比,進入對比頁面。
3. 公開數據集評測對比結果
 粵公網安備 44030702001206號
粵公網安備 44030702001206號