
友盟+ 簡介
友盟+ 以“數據智能,驅動業務增長”為使命,為移動應用開發者和企業提供包括統計分析、性能監測、消息推送、智能認證等一站式解決方案。截止2023年6月,已累計為270萬移動應用和980萬家網站,提供十余年的專業數據服務。
作為國內最大的移動應用統計服務商,其統計分析產品 U-App & U-Mini & U-Web 為開發者提供基礎報表及自定義用戶行為分析服務,能夠幫助開發者更好地理解用戶需求,優化產品功能,提升用戶體驗,助力業務增長。

為了滿足產品、運營等多業務角色對數據不同視角的分析需求,統計分析 U-App 提供了包括用戶分析、頁面路徑、卸載分析在內的多種「開箱即用」的預置報表,集成 SDK 上報數據后即可查看這些指標。除此以外,為了滿足個性化的分析訴求,業務也可以自定義報表的計算規則,提供了事件細分、漏斗分析、留存分析等用戶行為分析模型,用戶可以根據自己的分析需求靈活地選擇時間范圍、設置事件名稱、where篩選和Groupby分組等。
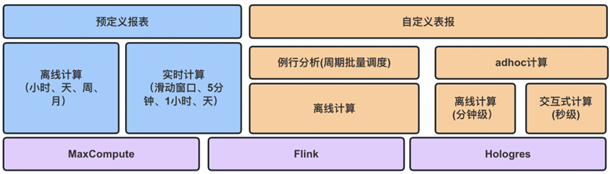
如上所述,U-App 服務了眾多應用場景,每天處理接近千億條日志,需要考慮平衡好數據新鮮度、查詢延遲和成本的關系,同時保障系統的穩定性,這對數據架構和技術選型提出了極高的要求。
針對報表類型不同的看數場景和業務需求,我們底層技術架構通過多種產品來支撐。在數據新鮮度方面,分別使用 Flink 和 MaxCompute 提供了T+0 的實時計算 和 T+1的離線批量計算,主要支持預置報表的計算場景,并將計算好的結果導出到類Hbase 存儲,能夠支持高并發的報表查詢。在分析時效性方面,使用阿里云的Hologres 實現自定義報表支持秒級的 OLAP分析,當處理的數據周期跨度大時,可能會出超過內存算子處理范圍,因此我們轉化為離線計算引擎來執行,同時也讓交互體驗從同步降級為異步。
在本文中,我們會分享友盟U-App 背后的技術實現,以及友盟在行為分析和畫像分析場景上的最佳實踐。
友盟+技術架構
如下圖所示,在大數據領域這是一個比較通用的數據處理 pipeline,貫穿數據的加工&使用過程包括,數據采集&接入、數據清洗&傳輸、數據建模&存儲、數據計算&分析 以及 查詢&可視化,其中友盟U-App 數據處理的核心架構是紅框部分。
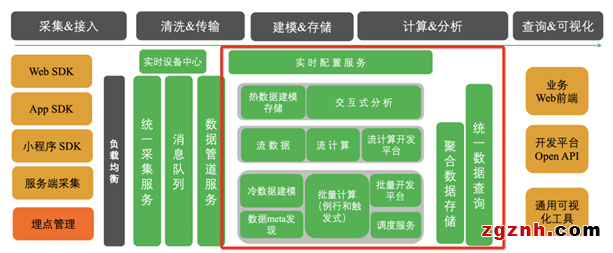
U-App 整體架構如下圖所示,從上往下大體可以分為四層:數據服務、數據計算、數據存儲以及核心組件:
數據服務:將查詢DSL 解析為底層引擎執行的DAG,同時智能采樣、查詢排隊等來盡可能減少系統過載情況,保證查詢順滑
數據計算:根據不同分析場景抽象沉淀了分析模型,包括行為分析和畫像分析兩大類
數據存儲:使用了以 User-Event 為核心的數據模型,提供基于明細數據的行為分析
核心組件:離線批量計算使用MaxCompute,流式計算使用Flink,OLAP計算使用Hologres
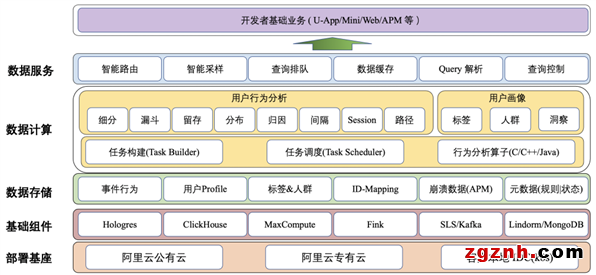
在設計系統架構時,支持多引擎是優先要考慮的,主要有以下原因:
鑒于成本、穩定性、高可用以及容錯性考慮,引擎需要根據查詢場景分級路由,將查詢性能好的OLAP計算與健壯可靠但延遲較大的離線計算相結合。用戶可以使用 OLAP 分析進行靈活的數據探查,當數據量超過一定閾值時自動轉為離線計算。另外,對于添加到看板需要例行查看的報表也會通過離線的方式批量計算。
鑒于存儲成本考慮,將數據進行冷熱分離,實時數倉只儲最近1個月熱數據,超過查詢范圍的Query會自動路由到離線計算。
從系統的可擴展性考慮,OLAP領域發展很快,眾多引擎百花齊放,需要為之后對接其它引擎預留出靈活的升級空間。
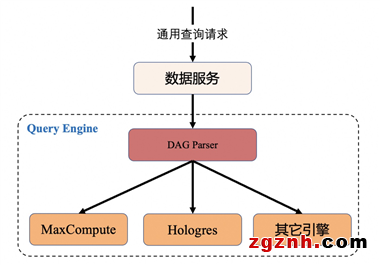
同時,我們也設計了一套通用的計算規則來支持多引擎架構,屏蔽底層細節。借鑒了Presto系統設計,選擇Antlr來定義通用的查詢規則,查詢DSL使用JSON來描述。Task Builder 在生成任務DAG時,遍歷AST抽樣語法樹,并結合物理表存儲等元數據信息,生成指定引擎可執行的語句。
通過自定義描述語言,上層業務只需要對接DSL不用關注底層細節,既降低了業務對接成本,也增強了平臺擴展性。

基于這套技術架構,我們服務了友盟+U-App 產品中的眾多應用場景。其中,基于明細數據的用戶行為分析和基于全域標簽的畫像分析是非常重要的兩個功能,其實現主要使用了阿里云Hologres,下面我們會詳細介紹這兩個場景上的最佳實踐。
Hologres多維分析使用實踐
在多維分析場景,尤其是用戶行為分析和畫像分析場景上,市面上可選擇的OLAP產品還是較多的。我們對集團多個引擎進行深入調研和測試后,最終選擇了阿里云計算平臺的Hologres,主要基于以下考慮:
存算分離架構:計算資源彈性伸縮,滿足靈活擴展性的同時又兼顧了成本。
生態豐富:語法與PostgreSQL函數兼容,我們使用起來的時候比較方便。同時我們也與Hologres團隊共建,支持了一些UDF函數,方便我們業務深度開展。
與MaxCompute深度集成:可以和MC互相直讀,加速查詢,實現實時離線聯邦查詢。同時也支持冷熱數據混合查詢,有利于成本性能平衡。
性能強悍:引擎C/C++編寫,支持量化全異步執行,PB級數據查詢秒級響應且支持數據實時寫入。
用戶行為分析實踐
U-App行為洞察提供了事件、漏斗、留存 、行為路徑等模型,可以幫助業務從多視角洞察用戶細粒度的使用行為,從而進一步輔助業務精細化運營。
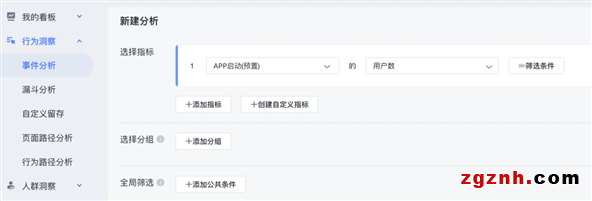
U-App 行為洞察提供的是普惠的交互式分析服務,這對技術的挑戰主要包括以下幾個方面:
數據量大,每天新增日志條數接近千億級別(注:為了保證查詢靈活性,分析使用的是沒有信息損失的事件原始數據,即沒有使用中間聚合表)
應用眾多,不同應用數據量差距較大
自定義埋點數據 schema-free ,不同應用埋點屬性差異巨大
計算分析速度要快并發要高
為了應對以上諸多挑戰,我們從存儲層、引擎執行層以及查詢層制定了系統性化的解決方案,下面依次進行介紹。
數據存儲層設置合理的索引
根據業務查詢特點,在Hologres中合理的建立索引,盡可能減少Scan的數據量:
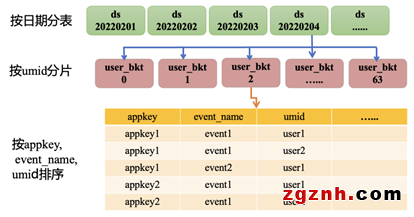
根據查詢特點(每個查詢只涉及一個應用的有限幾個事件),按照appkey,event_name建立聚簇索引(Clustering Key)
根據用戶行為分析的特點,按設備id分片(Distribution Key),數據在woker節點正交分布,減少跨節點數據 shuffle
設置合理shard數量,平衡數據寫入和查詢性能
對常用篩選列建立Bitmap索引,提升數據過濾效率
在埋點場景上,開發者可設置自定義事件和屬性,自定義屬性使用 JSON 字符串表示。JSON 優點是天然支持 Schema Evoluation,開發者根據業務需求,靈活進行埋點。缺點是較列式存儲,由于無法利用列存對數據進行壓縮,占用存儲空間大,而且查詢 JSON 時要將整個字符串完整解析一遍,中間涉及大量IO和CPU操作,對性能影響極大。
為解決這個問題,業界較通用的方案是在預處理階段,動態地將JSON展開成獨立列,通過外部的元數據表來維護 schema。另外,為了減少 schema 變動,也可以提前創建預留列,然后將新抽取的列映射到預設列上。但友盟+服務了眾多開發者 ,不可能將所有的屬性都展開成獨立列---即使可以做到,使用和維護成本也相當高。
借助 Hologres v1.3版本的JSONB列式存儲特效,支持在導入JSON 數據時,引擎自動抽取JSON數據結構,包括字段個數,字段類型等,然后在存儲層將JSON數據轉化成強 Schema格式的列式存儲格式的文件,以此來達到加速查詢的效果。通過測試,使用 JSONB 后,數據存儲會節省 25~50%,查詢效率提升 5~10 倍。
引擎執行層使用行為分析函數
為了提升查詢性能,我們與Hologres合作共建了自定義的分析函數函數,它主要解決兩個問題:
漏斗、留存這類分析模型,使用普通JOIN計算性能較差,尤其是漏斗分析,隨著計算事件數的增加,時間復雜度會指數級放大。
原生SQL表達能力差,無法描述計算邏輯復雜的模型。為了解決以上問題,需要開發自定義的分析函數 。
具體實現是基于Hologres的引擎,兼容PostgreSQL語法,使用C語言定制開發了漏斗和留存算子,集成在Hologres的版本中(最開始的發布的版本是0.8版本)。目前在Hologres高版本中默認已經集成了計算漏斗和留存的流量函數(windowFunnel,retention等),以及成為系統的標配,使用起來更加方便,性能也更好。
例如下面是一個漏斗分析的示例,計算在 20231220 這一天,在 1 小時內 依次發生從啟動(session_start)-> 加購物車(add_cart)-> 支付訂單(order_pay)3 個事件的轉化漏斗,我們對比了傳統JOIN方案和漏斗函數的方案的性能性能。

第一個是純SQL的方式,第二個是用 Hologres windowFunne 聚合函數。使用第一個JOIN SQL會有性能問題,因為存在多步JOIN操作,隨著計算事件量的增加,時間復雜度會指數級放大。而第二個使用漏斗函數的SQL則變得簡單許多。
下面是使用普通JOIN與漏斗函數的性能測試對比情況:在事件量較小的情況下,二者性能差距不大,但隨著事件量的增加,普通JOIN查詢性能迅速衰減,而使用漏斗函數的耗時較平緩。與普通的JOIN 查詢相比,使用漏斗函數的查詢速度提升了 5~10 倍,內存使用量下降 10%~25%。
數據查詢層使用智能采樣、查詢排隊
智能采樣:由于OLAP是完全基于內存的計算,為了避免較大查詢引發系統OOM,保障查詢吞吐和系統穩定性,對于數據量較大的 Query 會主動采樣。通過分析查詢條件,結合預先統計的信息可以預估出Scan的數據量,然后再結合提前設置好的閾值確定采樣率。平臺上線初期,智能采樣發揮了很大的作用。
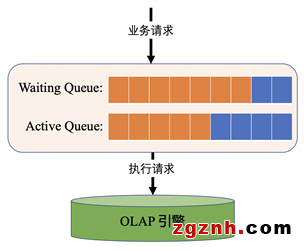
查詢排隊:為了解決瞬時高并發查詢引發的系統過載的問題,基于Redis實現了查詢排隊功能。如下圖所示,它包含Waiting Queue和Active Queue兩部分,所有請求先進入等待隊列排隊,并控制進入執行隊列的數量,從而避免系統過載,大幅提升了查詢的順滑性。
標簽人群計算實踐
友盟+基于采集的設備信息產出了豐富維度的標簽數據。依托這些數據,U-App提供的全景畫像功能可以對數據進行詳細刻畫。
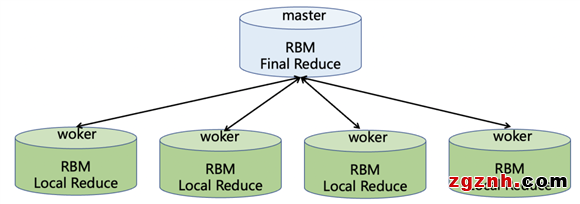
為了實現畫像的高性能多維分析,我們使用了Hologres的Roaring Bitmap功能。在具體數據存儲上,為了充分發揮 Hologres 多 shard 的并發優勢,數據的分布鍵(Distribution Key)按桶號和 bitmap 高16位打散到Hologres各個計算節點。在進行交并差集計算過程中,由于各個節點之間數據完全獨立,每個節點可以單獨計算,然后在Master節點進行匯總。
計算過程如下圖所示,整個過程可以分為兩個階段:在Worker節點會進行第一次聚合,由于Worker間數據完全正交,數據沒有shuffle過程,不需要跨幾點轉移數據,效率會非常高;在Master節點進行最終聚合通過簡單匯總得到最終結果。
基于以上 Hologres 的Roaring Bitmap設計,一個完整的標簽場景從數據導入和查詢示例如下:

通過使用 Hologres 提供的 Roaring Bitmap 功能,使用的存儲大大減少,相較之前大概有 5~10 倍的節省。查詢性能方面,與普通的 JOIN 相比,兩個億級別ID的標簽復合運算的可以有數量級的性能提升,90%的 Query 能夠在1秒內穩定完成,滿足了業務上對高吞吐和即時分析的需求。
總結與展望
目前,Hologres 在友盟+統計分析、營銷等多個產品線使用,很好地滿足了用戶行為分析、人群圈選與洞察場景的多維度分析、靈活下鉆、快速人群預估和圈選等分析需求,提供客戶更流暢的數據查詢和分析體驗。
未來,隨著互聯網流量紅利消失,拉新和留存成本升高,精細化數據運營越來越被重視,對于數據分析的時效性和靈活性的要求變得越來越高,實時OLAP數據分析會成為一種基本需求,這對技術的挑戰也越來越大。技術上,后續會結合Hologres物化視圖、冷熱數據分離等新特性,同時探索基于Apache Paimon 的 Streaming LakeHouse 存儲技術,不斷優化精簡架構,在平衡好性能、成本和穩定性基礎上,提升計算平臺實時計算能力,為開發者提供更好用的普惠的數據分析服務。
 粵公網安備 44030702001206號
粵公網安備 44030702001206號